


動作識別和檢測等對人類行為的分析是計算機視覺領域一個基礎而又困難的任務,也有很廣泛的應用范圍,比如智能監(jiān)控系統(tǒng)、人機交互、游戲控制和機器人。鉸接式的人體姿態(tài)(也被稱為骨架(skeleton))能為描述人體動作提供非常好的表征。一方面,骨架數(shù)據(jù)在背景噪聲中具有固有的穩(wěn)健性,并且能提供人體動作的抽象信息和高層面特征。另一方面,與 RGB 數(shù)據(jù)相比,骨架數(shù)據(jù)的規(guī)模非常小,這讓我們可以設計出輕量級且硬件友好的模型。
本論文關注的是基于骨架的人體動作識別和檢測問題(圖 1)。骨架的相互作用和組合在描述動作特征上共同發(fā)揮了關鍵性作用。有很多早期研究都曾試圖根據(jù)骨架序列來設計和提取共現(xiàn)特征(co-occurrence feature),比如每個關節(jié)的配對的相對位置 [Wang et al., 2014]、配對關節(jié)的空間方向 [Jin and Choi, 2012]、Cov3DJ [Hussein et al., 2013] 和 HOJ3D [Xia et al., 2012] 等基于統(tǒng)計的特征。另一方面,帶有長短期記憶(LSTM)神經(jīng)元的循環(huán)神經(jīng)網(wǎng)絡(RNN)也常被用于建模骨架的時間序列 [Shahroudy et al., 2016; Song et al., 2017; Liu et al., 2016]。盡管 LSTM 網(wǎng)絡就是為建模長期的時間依賴關系而設計的,但由于時間建模是在原始輸入空間上完成的,所以它們難以直接從骨架上學習到高層面的特征 [Sainath et al., 2015]。而全連接層則有能力聚合所有輸入神經(jīng)元的全局信息,進而可以學習到共現(xiàn)特征。[Zhu et al., 2016] 提出了一種端到端的全連接深度 LSTM 網(wǎng)絡來根據(jù)骨架數(shù)據(jù)學習共現(xiàn)特征。
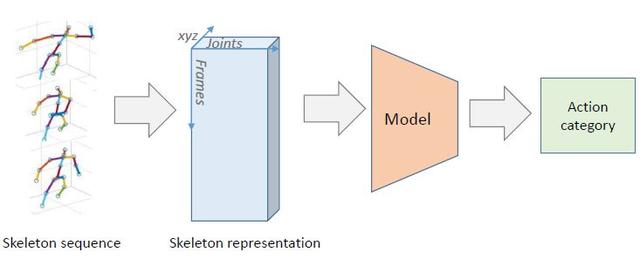
圖 1:基于骨架的人體動作識別的工作流程
CNN 模型在提取高層面信息方面能力出色,并且也已經(jīng)被用于根據(jù)骨架學習空間-時間特征 [Du et al., 2016; Ke et al., 2017]。這些基于 CNN 的方法可以通過將時間動態(tài)和骨架關節(jié)分別編碼成行和列而將骨架序列表示成一張圖像,然后就像圖像分類一樣將圖像輸入 CNN 來識別其中含有的動作。但是,在這種情況下,只有卷積核內(nèi)的相鄰關節(jié)才被認為是在學習共現(xiàn)特征。盡管感受野(receptive field)能在之后的卷積層中覆蓋骨架的所有關節(jié),但我們很難有效地從所有關節(jié)中挖掘共現(xiàn)特征。由于空間維度中的權重共享機制,CNN 模型無法為每個關節(jié)都學習自由的參數(shù)。這促使我們設計一個能獲得所有關節(jié)的全局響應的模型,以利用不同關節(jié)之間的相關性。
我們提出了一種端到端的共現(xiàn)特征學習框架,其使用了 CNN 來自動地從骨架序列中學習分層的共現(xiàn)特征。我們發(fā)現(xiàn)一個卷積層的輸出是來自所有輸入通道的全局響應。如果一個骨架的每個關節(jié)都被當作是一個通道,那么卷積層就可以輕松地學習所有關節(jié)的共現(xiàn)。更具體而言,我們將骨架序列表示成了一個形狀幀×關節(jié)×3(最后一維作為通道)的張量。我們首先使用核大小為 n×1 的卷積層獨立地為每個關節(jié)學習了點層面的特征。然后我們再將該卷積層的輸出轉(zhuǎn)置,以將關節(jié)的維度作為通道。在這個轉(zhuǎn)置運算之后,后續(xù)的層分層地聚合來自所有關節(jié)的全局特征。此外,我們引入了一種雙流式的框架 [Simonyan and Zisserman, 2014] 來明確地融合骨架運動特征。
本研究工作的主要貢獻總結如下:
-
我們提出使用 CNN 模型來學習骨架數(shù)據(jù)的全局共現(xiàn)特征,研究表明這優(yōu)于局部共現(xiàn)特征。
-
我們設計了一種全新的端到端分層式特征學習網(wǎng)絡,其中的特征是從點層面特征到全局共現(xiàn)特征逐漸聚合起來的。
-
我們?nèi)娴厥褂昧硕嗳颂卣魅诤喜呗裕@讓我們的網(wǎng)絡可以輕松地擴展用于人數(shù)不同的場景。
-
在動作識別和檢測任務的基準上,我們提出的框架優(yōu)于所有已有的當前最佳方法。
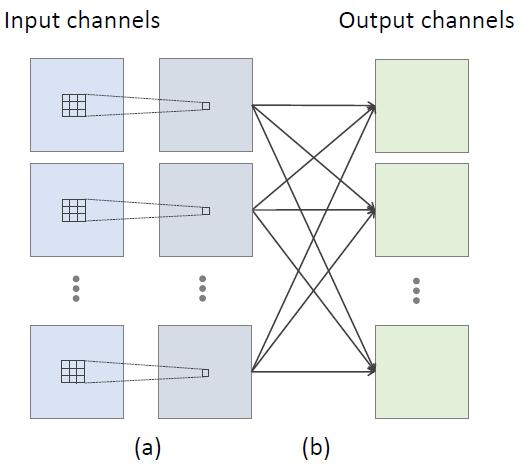
圖 2:3×3 卷積的分解分為兩個步驟。(a) 每個輸入通道的空間域中的獨立 2D 卷積,其中的特征是從 3×3 的臨近區(qū)域局部聚合的。(b) 各個通道上逐個元素求和,其中的特征是在所有輸入通道上全局地聚合。
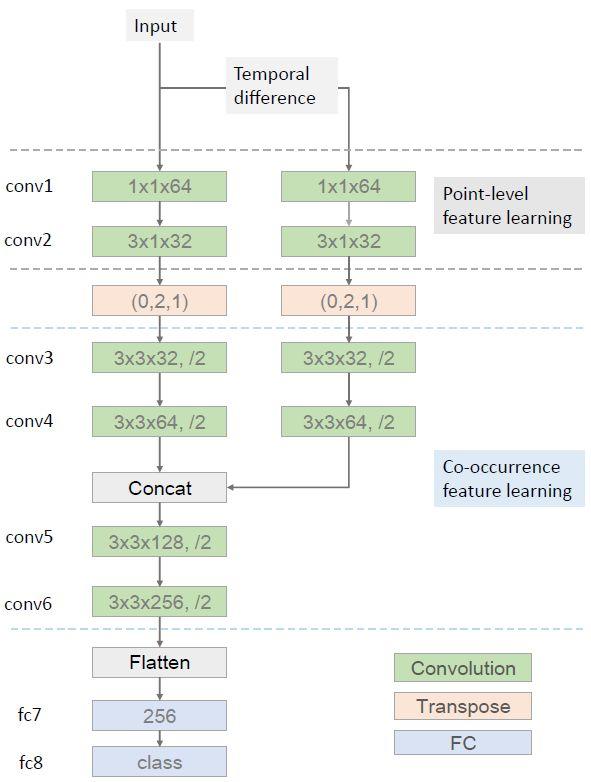
圖 3:我們提出的分層式共現(xiàn)網(wǎng)絡(HCN:Hierarchical Co-occurrence Network)的概況。綠色模塊是卷積層,其中最后一維表示輸出通道的數(shù)量。后面的「/2」表示卷積之后附帶的最大池化層,步幅為 2。轉(zhuǎn)置層是根據(jù)順序參數(shù)重新排列輸入張量的維度。conv1、conv5、conv6 和 fc7 之后附加了 ReLU 激活函數(shù)以引入非線性。
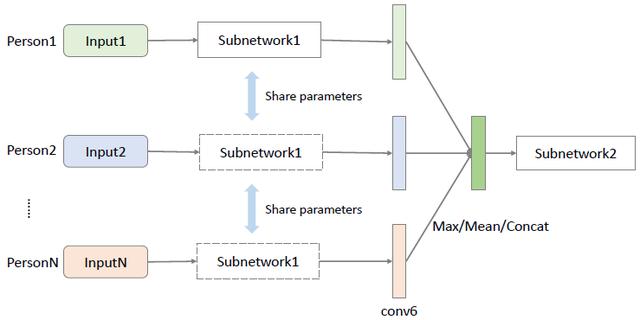
圖 4:用于多人特征融合的后期融合(late fusion)圖。最大、平均和連接操作在表現(xiàn)和泛化性能上得到了評估。
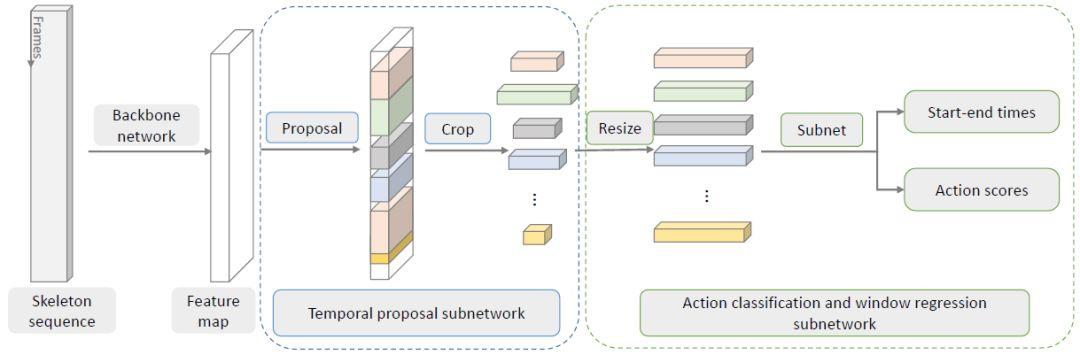
圖 5:時間動作檢測框架。圖 3 描述了其中的骨干網(wǎng)絡。還有兩個子網(wǎng)絡分別用于時間上提議的分割和動作分類。
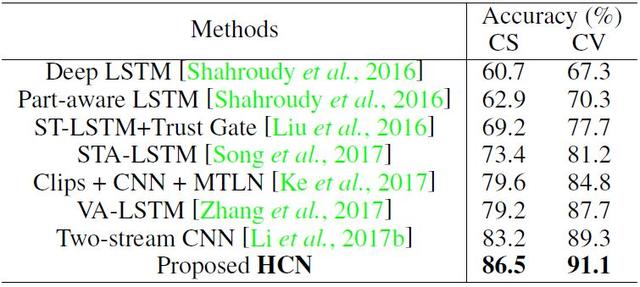
表 2:在 NTU RGB+D 數(shù)據(jù)集上的動作分類表現(xiàn)。CS 和 CV 分別表示 cross-subject 和 cross-view 的設置。
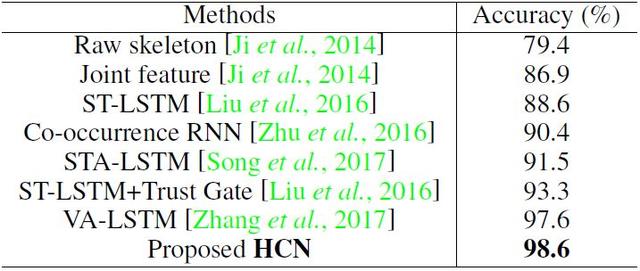
表 3:在 SBU 數(shù)據(jù)集上的動作分類表現(xiàn)。
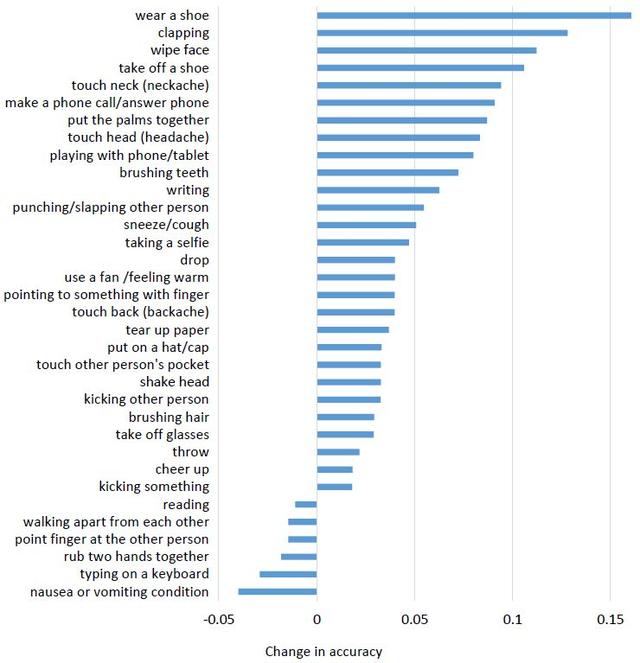
圖 6:在 NTU RGB+D 數(shù)據(jù)集上的 cross-subject 設置中,在每個類別上 HCN 相對于 HCN-local 的準確度變化。為了清楚簡明,這里只給出了變化超過 1% 的類別。
論文:使用分層聚合實現(xiàn)用于動作識別和檢測的基于骨架數(shù)據(jù)的共現(xiàn)特征學習(Co-occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation)

論文鏈接:https://arxiv.org/abs/1804.06055
摘要:隨著大規(guī)模骨架數(shù)據(jù)集變得可用,基于骨架的人體動作識別近來也受到了越來越多的關注。解決這一任務的最關鍵因素在于兩方面:用于關節(jié)共現(xiàn)的幀內(nèi)表征和用于骨架的時間演化的幀間表征。我們在本論文中提出了一種端到端的卷積式共現(xiàn)特征學習框架。這些共現(xiàn)特征是用一種分層式的方法學習到的,其中不同層次的環(huán)境信息(contextual information)是逐漸聚合的。首先獨立地編碼每個節(jié)點的點層面的信息。然后同時在空間域和時間域?qū)⑺鼈兘M合成形義表征。具體而言,我們引入了一種全局空間聚合方案,可以學習到優(yōu)于局部聚合方法的關節(jié)共現(xiàn)特征。此外,我們還將原始的骨架坐標與它們的時間差異整合成了一種雙流式的范式。實驗表明,我們的方法在 NTU RGB+D、SBU Kinect Interaction 和 PKU-MMD 等動作識別和檢測基準上的表現(xiàn)能穩(wěn)定地優(yōu)于其它當前最佳方法。




















