


sql優(yōu)化問題
sql語句性能達不到你的要求,執(zhí)行效率讓你忍無可忍,一般會時下面幾種情況。
§ 網(wǎng)速不給力,不穩(wěn)定。
§ 服務(wù)器內(nèi)存不夠,或者SQL 被分配的內(nèi)存不夠。
§ sql語句設(shè)計不合理
§ 沒有相應(yīng)的索引,索引不合理
§ 沒有有效的索引視圖
§ 表數(shù)據(jù)過大沒有有效的分區(qū)設(shè)計
§ 數(shù)據(jù)庫設(shè)計太2,存在大量的數(shù)據(jù)冗余
§ 索引列上缺少相應(yīng)的統(tǒng)計信息,或者統(tǒng)計信息過期
§ ....
那么我們?nèi)绾谓o找出來導(dǎo)致性能慢的的原因呢?
§ 首先你要知道是否跟sql語句有關(guān),確保不是機器開不開機,服務(wù)器硬件配置太差,沒網(wǎng)你說p啊
§ 接著用sql性能檢測工具--sql server profiler,分析出sql慢的相關(guān)語句,就是執(zhí)行時間過長,占用系統(tǒng)資源,cpu過多的
§ 然后是這篇文章要說的,sql優(yōu)化方法跟技巧,避免一些不合理的sql語句,取暫優(yōu)sql
§ 再然后判斷是否使用啦,合理的統(tǒng)計信息。sql server中可以自動統(tǒng)計表中的數(shù)據(jù)分布信息,定時根據(jù)數(shù)據(jù)情況,更新統(tǒng)計信息,是很有必要的
§ 確認(rèn)表中使用啦合理的索引
§ 數(shù)據(jù)太多的表,要分區(qū),縮小查找范圍
分析比較執(zhí)行時間計劃讀取情況
select * from dbo.Product
執(zhí)行上面語句一般情況下只給你返回結(jié)果和執(zhí)行行數(shù),那么你怎么分析呢,怎么知道你優(yōu)化之后跟沒有優(yōu)化的區(qū)別呢。
下面給你說幾種方法。
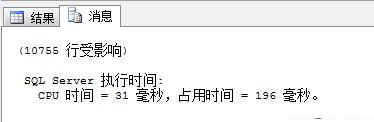
1.查看執(zhí)行時間和cpu占用時間
set statistics time on
select * from dbo.Product
set statistics time off
打開你查詢之后的消息里面就能看到啦。
2.查看查詢對I/0的操作情況
set statistics io on
select * from dbo.Product
set statistics io off
執(zhí)行之后

掃描計數(shù):索引或表掃描次數(shù)
邏輯讀取:數(shù)據(jù)緩存中讀取的頁數(shù)
物理讀取:從磁盤中讀取的頁數(shù)
預(yù)讀:查詢過程中,從磁盤放入緩存的頁數(shù)
lob邏輯讀取:從數(shù)據(jù)緩存中讀取,image,text,ntext或大型數(shù)據(jù)的頁數(shù)
lob物理讀取:從磁盤中讀取,image,text,ntext或大型數(shù)據(jù)的頁數(shù)
lob預(yù)讀:查詢過程中,從磁盤放入緩存的image,text,ntext或大型數(shù)據(jù)的頁數(shù)
如果物理讀取次數(shù)和預(yù)讀次說比較多,可以使用索引進行優(yōu)化。
如果你不想使用sql語句命令來查看這些內(nèi)容,方法也是有的,哥教你更簡單的。
查詢--->>查詢選項--->>高級
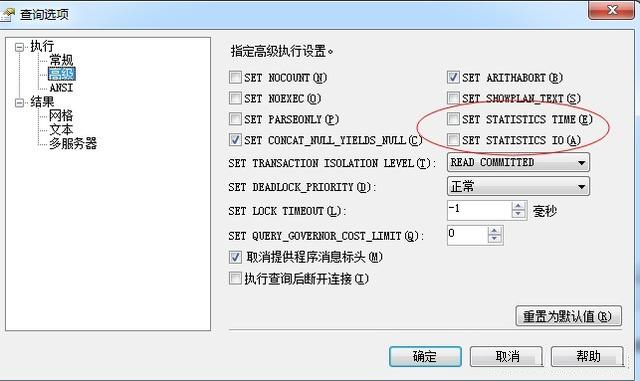
被紅圈套上的2個選上,去掉sql語句中的set statistics io/time on/off 試試效果。哦也,你成功啦。。
3.查看執(zhí)行計劃,執(zhí)行計劃詳解
選中查詢語句,點擊

然后看消息里面,會出現(xiàn)下面的圖例
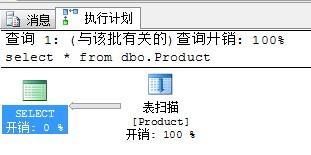
select查詢藝術(shù)
1.保證不查詢多余的列與行。
§ 盡量避免select * 的存在,使用具體的列代替*,避免多余的列
§ 使用where限定具體要查詢的數(shù)據(jù),避免多余的行
§ 使用top,distinct關(guān)鍵字減少多余重復(fù)的行
2.慎用distinct關(guān)鍵字
distinct在查詢一個字段或者很少字段的情況下使用,會避免重復(fù)數(shù)據(jù)的出現(xiàn),給查詢帶來優(yōu)化效果。
但是查詢字段很多的情況下使用,則會大大降低查詢效率。
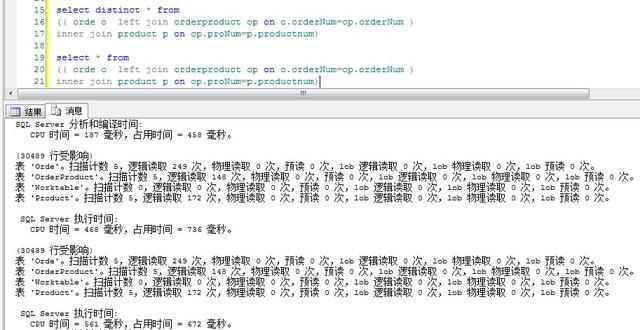
由這個圖,分析下:
很明顯帶distinct的語句cpu時間和占用時間都高于不帶distinct的語句。原因是當(dāng)查詢很多字段時,如果使用distinct,數(shù)據(jù)庫引擎就會對數(shù)據(jù)進行比較,過濾掉重復(fù)數(shù)據(jù),然而這個比較,過濾的過程則會毫不客氣的占用系統(tǒng)資源,cpu時間。
3.慎用union關(guān)鍵字
此關(guān)鍵字主要功能是把各個查詢語句的結(jié)果集合并到一個結(jié)果集中返回給你。用法
<select 語句1>
union
<select 語句2>
union
<select 語句3>
...
滿足union的語句必須滿足:1.列數(shù)相同。 2.對應(yīng)列數(shù)的數(shù)據(jù)類型要保持兼容。
執(zhí)行過程:
依次執(zhí)行select語句-->>合并結(jié)果集--->>對結(jié)果集進行排序,過濾重復(fù)記錄。
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum) where p.id<10000
union
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum) where p.id<20000 and p.id>=10000
union
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum) where p.id>20000
---這里可以寫p.id>100 結(jié)果一樣,因為篩選過
----------------------------------對比上下兩個語句-----------------------------------------
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum )
inner join product p on op.proNum=p.productnum)
由此可見效率確實低,所以不是在必要情況下避免使用。其實有他執(zhí)行的第三部:對結(jié)果集進行排序,過濾重復(fù)記錄。就能看出不是什么好鳥。然而不對結(jié)果集排序過濾,顯然效率是比union高的,那么不排序過濾的關(guān)鍵字有嗎?答,有,他是union all,使用union all能對union進行一定的優(yōu)化。。
4.判斷表中是否存在數(shù)據(jù)
select count(*) from product
select top(1) id from product
很顯然下面完勝
5.連接查詢的優(yōu)化
首先你要弄明白你想要的數(shù)據(jù)是什么樣子的,然后再做出決定使用哪一種連接,這很重要。
各種連接的取值大小為:
§ 內(nèi)連接結(jié)果集大小取決于左右表滿足條件的數(shù)量
§ 左連接取決與左表大小,右相反。
§ 完全連接和交叉連接取決與左右兩個表的數(shù)據(jù)總數(shù)量
select * from
( (select * from orde where OrderId>10000) o left join orderproduct op on o.orderNum=op.orderNum )
select * from
( orde o left join orderproduct op on o.orderNum=op.orderNum )
where o.OrderId>10000
由此可見減少連接表的數(shù)據(jù)數(shù)量可以提高效率。
總結(jié)
優(yōu)化,最重要的是在于你平時設(shè)計語句,數(shù)據(jù)庫的習(xí)慣,方式。如果你平時不在意,匯總到一塊再做優(yōu)化,你就需要耐心的分析,然而分析的過程就看你的悟性,需求,知識水平啦。




















