



Mask-RCNN進行目標檢測和實例分割
想做計算機視覺?深度學習是最近的發(fā)展方向。大規(guī)模數據集加上深度卷積神經網絡(CNNs)的表征能力使得超精確和穩(wěn)健的模型成為可能。現(xiàn)在只剩下一個挑戰(zhàn):如何設計你的模型。
由于計算機視覺領域廣泛而復雜,因此解決方案并不總是很清晰。計算機視覺中的許多標準任務都需要特別考慮:分類,檢測,分割,姿態(tài)估計,增強和恢復,動作識別。盡管用于每個任務的最先進的網絡表現(xiàn)出共同的模式,但他們都需要自己獨特的設計風格。
那么我們如何為所有這些不同的任務建立模型呢?
讓我來告訴你如何用深度學習在計算機視覺中做所有事情!
分類
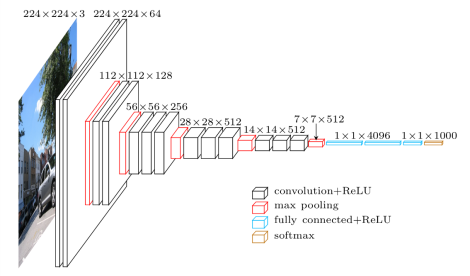
所有任務中最為人所知的!圖像分類網絡以固定尺寸的輸入開始。輸入圖像可以具有任意數量的通道,但對于RGB圖像通常為3。在設計網絡時,分辨率在技術上可以是任何尺寸,只要它足夠大以支持你將在整個網絡中執(zhí)行的下采樣數量。例如,如果您在網絡中進行4次下采樣,那么您的輸入尺寸需要至少為 4² = 16 x 16 像素。
當你進入網絡更深層時,空間分辨率將會降低,就像我們盡力擠壓所有信息并降低到一維向量表示。為了確保網絡始終具有繼承其提取的所有信息的能力,我們根據深度按比例增加特征圖的數量以適應空間分辨率的降低。也就是說,我們在下采樣過程中丟失了空間信息,為了適應損失,我們擴展了我們的特征圖以增加我們的語義信息。
在你選擇了一定數量的下采樣后,特征圖會被矢量化并送入一系列全連接層。最后一層的輸出與數據集中的類一樣多。
目標檢測
目標檢測器有兩種形式:單階段和兩階段。它們兩者都以“錨框”開始;這些是默認的邊界框。我們的檢測器將預測這些方框與邊界框真值之間的差異,而不是直接預測方框。
在兩階段檢測器中,我們自然有兩個網絡:一個框提議網絡和一個分類網絡。框提議網絡得到了邊界框的坐標,它認為目標在這里的可能性很大;再次提醒,這些坐標都是相對于錨框的。然后,分類網絡獲取每個邊界框并對其中的潛在物體進行分類。
在單階段檢測器中,提議和分類器網絡被融合到一個單獨的階段中。網絡直接預測邊界框坐標和在該框內物體的類別。因為兩個階段融合在一起,所以單階段檢測器往往比兩階段更快。但是由于兩個任務的分離,兩階段檢測器具有更高的精度。
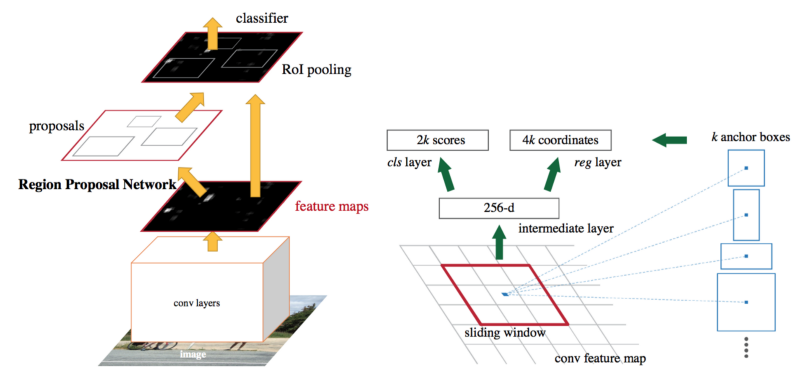
Faster-RCNN 兩階段目標檢測架構
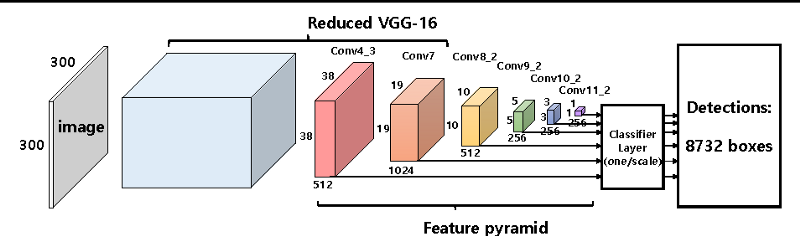
SSD 一階段目標檢測架構
分割
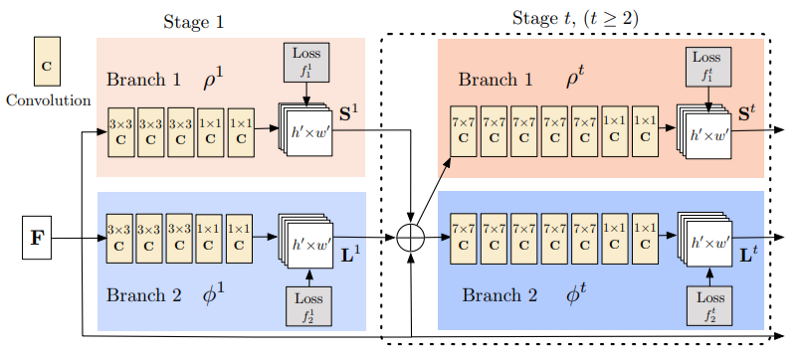
分割是計算機視覺中更獨特的任務之一,因為網絡需要學習低級和高級信息。低級信息通過像素精確地分割圖像中的每個區(qū)域和物體,而高級信息用于直接對這些像素進行分類。這就需要將網絡設計成結合低級信息和高級信息的結構,其中低級空間信息來自于前面層且是高分辨率的,高級語義信息來自于較深層且是低分辨率的。
正如我們在下面看到的,我們首先在標準分類網絡上運行我們的圖像。然后,我們從網絡的每個階段提取特征,從而使用從低到高的級別內的信息。每個級別的信息都是獨立處理的,然后依次將它們組合在一起。在組合信息時,我們對特征圖進行上采樣以最終獲得完整的圖像分辨率。
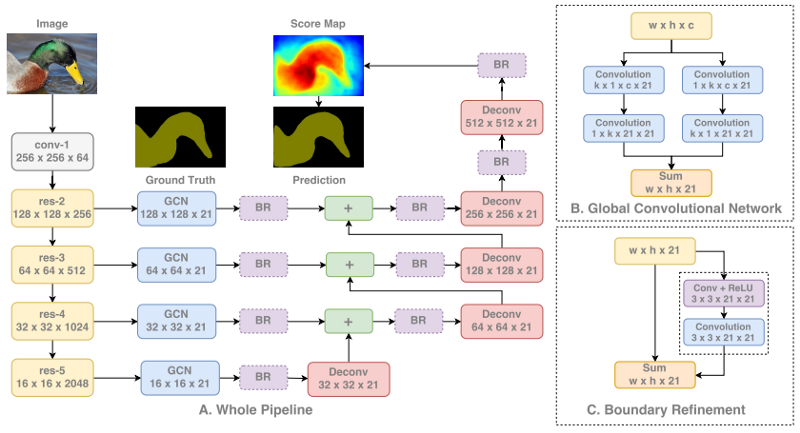
GCN分割架構
姿態(tài)估計
姿態(tài)估計模型需要完成兩個任務:(1)檢測每個身體部位圖像中的關鍵點(2)找出如何正確連接這些關鍵點的方式。這分為三個階段:
1、使用標準分類網絡從圖像中提取特征
2、鑒于這些特點,訓練一個子網絡來預測一組2D熱力圖。每張熱力圖都與一個特定的關鍵點相關聯(lián),并且包含每個圖像像素是否可能存在關鍵點的置信值。
3、再次給出分類網絡的特征,我們訓練一個子網絡來預測一組2D向量場,其中每個向量場編碼關鍵點之間的關聯(lián)度。具有高度關聯(lián)性的關鍵點就稱其為連接的。
以這種方式訓練模型與子網絡將共同優(yōu)化檢測關鍵點并將它們連接在一起。
開放式姿態(tài)估計體系結構
增強和恢復
增強和恢復網絡是它們自己的獨特之處。因為我們真正關心的是高像素/空間精度,所以我們不會對這些進行任何降采樣。降采樣真的會殺死這些信息,因為它會減少我們空間精度的許多像素。相反,所有的處理都是在完整的圖像分辨率下完成的。
我們首先將要增強/恢復的圖像以全解析度傳遞到我們的網絡,而不進行任何修正。網絡僅僅由一堆卷積和激活函數組成。這些塊通常是最初為圖像分類而開發(fā)的那些塊的靈感,有時是直接副本,例如殘余塊、密集塊、擠壓激勵塊等。由于我們希望直接預測圖像像素,不需要任何的概率或分數,所以在最后一層上沒有激活功能,甚至沒有sigmoid或softmax。。
這就是所有這些類型的網絡!在圖像的全解析度下進行大量的處理,以獲得高空間精度,這些使用已經證明與其他任務相同的卷積。
EDSR超分辨率架構
行為識別
動作識別是少數幾個需要視頻數據才能正常工作的應用之一。要對一個動作進行分類,我們需要知道隨著時間的推移場景發(fā)生的變化;這導致我們需要視頻。所以我們的網絡必須訓練以學習空間和時間信息。也就是空間和時間的變化。最適合的網絡是3D-CNN。
3D- CNN,顧名思義,就是一個使用3D卷積的卷積網絡!它們不同于常規(guī)CNN的地方在于其卷積應用于三維空間:寬度、高度和時間。因此,每個輸出像素都是基于它周圍的像素和相同位置上的前幀和后幀中的像素進行計算預測的!
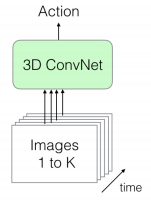
直接進行圖像的批量傳遞
視頻幀可以通過以下幾種方式傳遞:
(1)直接以大批量,如圖1所示。由于我們正在傳遞一組序列幀,因此空間和時間信息都是可用的
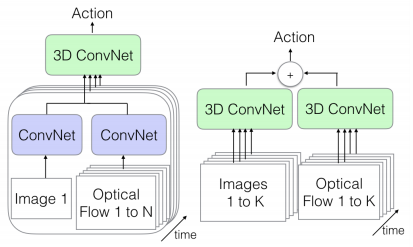
單幀+光流(左)。視頻+光流(右)
(2)我們還可以在一個流(數據的空間信息)中傳遞單個圖像幀,并從視頻(數據的時間信息)中傳遞其相應的光流表示。我們將使用常規(guī)的2D CNNs從兩者中提取特征,然后將它們組合起來傳遞給我們的3D CNN,它將組合這兩種類型的信息
(3)將我們的幀序列傳遞給一個3D CNN,將視頻的光流表示傳遞給另一個3D CNN。這兩個數據流都有可用的空間和時間信息。這可能是最慢的選項,但同時也可能是最準確的選項,因為我們正在對視頻的兩個不同表示進行特定的處理,這兩個表示都包含所有信息。
所有這些網絡都輸出視頻的動作分類。




















