谷歌、微軟、Facebook 等傳統(tǒng)的人工智能技術(shù)巨頭之外,百度近來也加入到了技術(shù)開源的浪潮之中,繼 PaddlePaddle 之后,百度又宣布開源了一項深度學習基準 DeepBench。
開源地址:https://github.com/baidu-research/DeepBench
1.DeepBench
DeepBench 是一個開源的基準工具,用來測量深度神經(jīng)網(wǎng)絡(luò)訓練中的基礎(chǔ)操作的表現(xiàn)。使用神經(jīng)網(wǎng)絡(luò)庫,這些操作在不同的硬件平臺被執(zhí)行。如今測試基準工具 DeepBench 在 github 上已經(jīng)開源。
DeepBench 的主要目標是 benchmark 對深度學習在不同硬件平臺上而言很重要的運算。盡管深度學習背后的基礎(chǔ)計算已經(jīng)被很好的理解了,但在實踐中它們被使用的方式驚人的不同。例如,矩陣相乘運算基于被相乘矩陣的大小和 Kernel 實現(xiàn),可能是 compute-bound,也可能是 bandwidth-bound, 或者 occupancy-bound。因為每個深度學習模型帶著不同的參數(shù)使用這些運算,面向深度學習硬件和軟件的優(yōu)化空間還是很大的,也是不足的。
DeepBench 試圖解決這個問題,「在被用于訓練深度神經(jīng)網(wǎng)絡(luò)時,在基礎(chǔ)運算上哪種硬件提供最好的表現(xiàn)?」我們在低層次上詳細說明了這些運算,建立深度學習處理器的團隊很適合在硬件模擬中使用 DeepBench。
1.1 DeepBench 適合用在哪里?
深度學習生態(tài)系統(tǒng)包含不同的模塊。我們想要強調(diào) DeepBench 適合用于該生態(tài)系統(tǒng)的哪部分。在下面的圖表中,描述了關(guān)于深度學習的軟件和硬件組件。在最頂端是百度的 PaddlePaddle、Theano、TensorFlow、Torch 等這樣的深度學習框架,這些框架使得我們能夠建立深度學習模型。它們包含層(layer)這樣的基礎(chǔ)建筑模塊,可通過不同的方式連接從而創(chuàng)造模型。為了訓練這些模型,框架使用英偉達的 cuDNN 和英特爾的 MKL 這樣的基礎(chǔ)神經(jīng)網(wǎng)絡(luò)庫。這些庫執(zhí)行矩陣相乘這樣的用來訓練深度學習模型的運算。最后,在英偉達 GPU 或英特爾 Xeon Phi 處理器這樣的硬件上訓練這些模型。
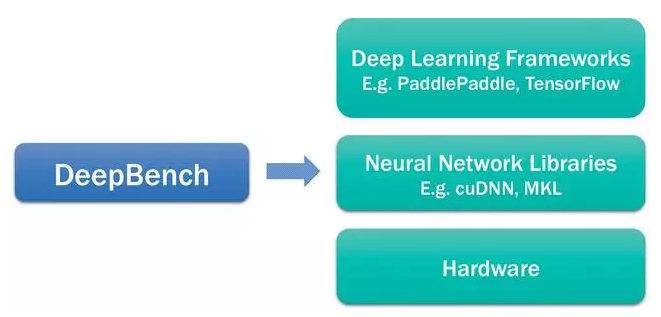
DeepBch 使用神經(jīng)網(wǎng)絡(luò)庫 benchmark 基礎(chǔ)運算在不同硬件上的表現(xiàn)。它對建立應(yīng)用的深度學習框架或深度學習模型沒用。我們不能測量使用 DeepBench 訓練整個模型所需要的時間。為不同應(yīng)用建立的模型的表現(xiàn)特性彼此間差別很大。因此,我們要 benchmark 涉及到深度學習模型訓練中的潛在運算。benchmark 這些運算有助于提高硬件供應(yīng)商的 意識,也有助于軟件開發(fā)者了解深度學習訓練的瓶頸。
1.2 方法論
DeepBench 包括一系列的基礎(chǔ)操作(稠密矩陣相乘、卷積和通信)以及一些循環(huán)層類型。在開源的代碼中有一個 Excel 表格描述了所有的大小。
前向和后向的運算都會被測試。該基準的第一代版本將注重在 32 位浮點算法中的訓練表現(xiàn)。未來的版本可能擴展到注重推理工作負載(inference workloads)和更低精度的算法。
即使存在更快的獨立庫或公開了更快的結(jié)果,我們也將使用供應(yīng)商提供的庫。大部分用戶將默認使用供應(yīng)商提供的庫,而且這種庫更代表用戶的體驗。
1.3. Entry
我們正在釋放在 4 個硬件平臺上的結(jié)果:英偉達的 TitanX、M40、TitanX Pacal 和英特爾的 Knights Landing。硬件供應(yīng)商或獨立用戶可運行大致的基準,并將結(jié)果輸入到表格中。
2. 運算的類型
2.1 稠密矩陣相乘
稠密矩陣相乘存在于大部分深度神經(jīng)網(wǎng)絡(luò)中。它們被用于執(zhí)行全連接層和 vanilla RNN,以及為其他類型的循環(huán)層建立基石。有時它們也被用作快速執(zhí)行新類層(在這里面自定義的代碼不存在)的方式。
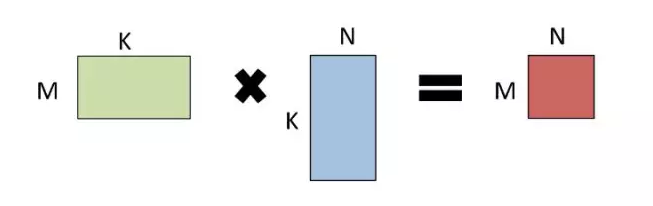
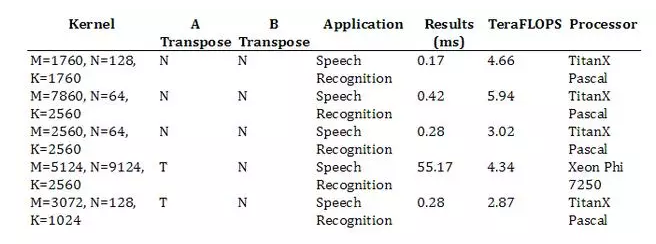
當執(zhí)行 GEMM 運算 A * B = C 時,A 和 B 中的一個或兩個都能被隨意的換位。描述一個矩陣問題的常用術(shù)語是 triple(M,N,K), 該術(shù)語描述了矩陣的大小。
2.2 卷積
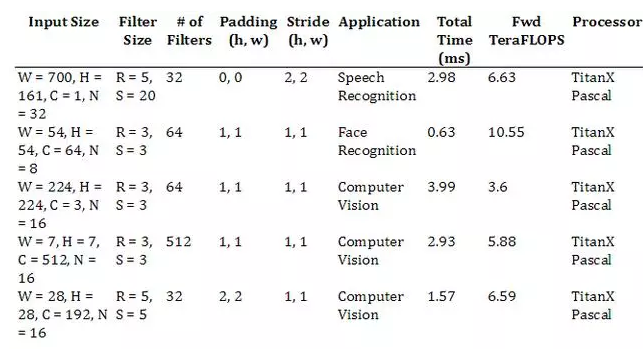
卷積構(gòu)成了網(wǎng)絡(luò)中在圖像和視頻操作上的絕大多數(shù)的浮點計算,也構(gòu)成了語音和自然語言模型網(wǎng)絡(luò)中的主要部分,從模型表現(xiàn)角度來看,它可能也是唯一最重要的層。
卷積有 4 或 5 維的輸入和輸出,為這些維提供了大量可能的排序。在改基準的第一代版本,我們只考慮了在 NCHW format 中的表現(xiàn),即數(shù)據(jù)是在圖像、特征映射、行和列中展示的。
有很多計算卷積的技術(shù)對不同大小的過濾器和圖像來說都是很好的選擇,包括:direct approaches、基于矩陣相乘的方法、基于 FFT 的方法以及基于 Winograd 的方法。在該基準的第一代版本,我們沒考慮不同方法的準確率,因為普遍共識是 32 位浮點計算對它們每個方法而言都是足夠準確的。
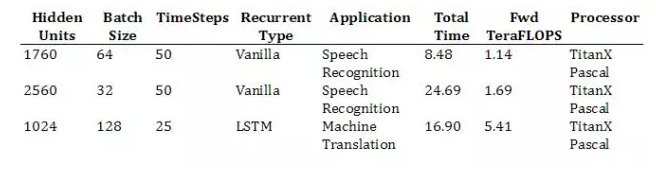
2.3 循環(huán)層(recurrent layers)
循環(huán)層總是由之前的運算與一元(unary)或二元(binary)運算這樣的簡單計算結(jié)合而成的——這些簡單運算不是計算密集型的,通常只需占據(jù)總體運算時間的一小部分。然而,在循環(huán)層中,GEMM 和卷積運算相對較小,所以這些更小運算的成本變得有極大影響。如果開始計算就有一個很高的固定成本,那上述內(nèi)容就尤其準確。也可以為循環(huán)矩陣使用額外的存儲格式,因為轉(zhuǎn)換成一個新的存儲格式的成本可被分攤到循環(huán)計算的許多步驟上。如果能做到這一點,那么從一個自定格式轉(zhuǎn)換或轉(zhuǎn)換成一個自定義格式的時間應(yīng)該被包含在整體時間之內(nèi)。
在一個時間步驟內(nèi)和跨序列的時間步驟上,這些因素會導致很多優(yōu)化的可能性,因此測定運算的原始性能并不一定能夠代表整個循環(huán)層的的性能。在這樣的基準上,我們僅關(guān)注一個循環(huán)層,即使還存在其它更多的優(yōu)化機會(如果考慮它們的層疊(stack))。
輸入的計算不應(yīng)該被包含在用于循環(huán)層計算的時間內(nèi),因為其可以作為一個大的乘法計算,然后被實際的循環(huán)運算所消化。所以在 h_t = g(Wx_t + Uh_t-1) 中,Wx_t 對于所有 t 的計算時間不應(yīng)被包含在循環(huán)層的時間內(nèi)。
反向計算應(yīng)該在考慮權(quán)重而非輸入的基礎(chǔ)上計算更新(update)。所有的循環(huán)工作完成以計算權(quán)重更新,所以同時考慮輸入來計算更新會掩蓋我們想要測定的內(nèi)容。
vanilla RNN 的非線性應(yīng)該是一個 ReLU。LSTM 的內(nèi)在非線性應(yīng)該是標準運算——門(gate)是 S 型函數(shù),激活(activation)是雙曲正切函數(shù)。LSTM 不應(yīng)該有窺視孔連接(peephole connections)。
2.4. All-Reduce
現(xiàn)在的神經(jīng)網(wǎng)絡(luò)通常在多 GPU 或多系統(tǒng)與 GPU 并行的情況下訓練,這主要有兩個技術(shù)分類:同步和異步。同步技術(shù)依賴于保持參數(shù)和所有模型實例的同步,它通常要保證在優(yōu)化步驟執(zhí)行前,所有模型實例有一些梯度的備份。最簡單運行這些計算結(jié)果的 Message Passing Interface (MPI) 被稱為 All-Reduce。有很多可以執(zhí)行 All-Reduce 的方法,我們可以依靠數(shù)字的排列、數(shù)據(jù)的大小和網(wǎng)絡(luò)的拓撲結(jié)構(gòu)來執(zhí)行。這種基準測試的方式在執(zhí)行時是沒有限制的,所以它的結(jié)果是不確定的。異步的方法則非常的不同,在這個版本的基準測試中我們不會測試這些方法。
為了評估 All-Reduce,我們使用了下面的庫和基準:NVIDIA's NCCL Ohio State University (OSU) Benchmarks
NCCL 庫包括一組標準的通信程序。這個庫支持在單個節(jié)點任意數(shù)量的 GPU 運行,并且它能在單個或多個進程中運行,但 NCC 程序不支持多節(jié)點下的 All-Reduce。為了能夠在多節(jié)點下評估 All-Reduce,我們使用了 OSU 下的 benchmark。我們在三個執(zhí)行過程中 (NCCL single process, NCCL MPI, OpenMPI) 報告了最短的延遲。
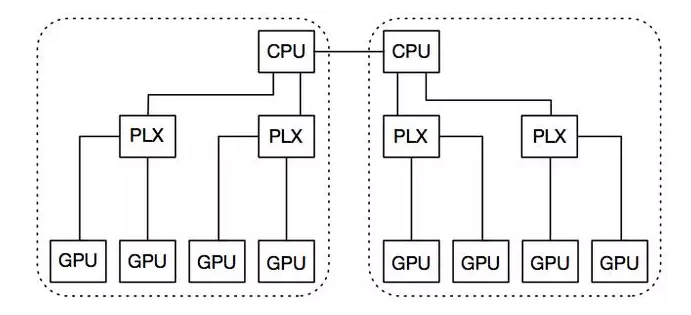
Nvidia 8 GPU 系統(tǒng)的拓撲結(jié)構(gòu)
每個節(jié)點都有兩個 GPU 插槽,而每個插槽都有一個 PCIe root complex。每個節(jié)點都有兩個 GPU 插槽,而每個插槽都有一個 PCIe root complex。每一套插槽都有兩個 PLX 開關(guān),它們通過 16 個 PCIe v3 的 lanes 各自連接到 CPU 插槽中。每個 PLX 插槽有兩個 GPU,所有的 GPU 通過 16 個 PCIe v3 的 lanes 進行同時通信。這兩個 CPU 插槽通過 Intel 的 QPI 連接,而跨界點的互聯(lián)則是通過 InfiniBand FDR。下圖顯示了一個原理圖的節(jié)點,在圖中,所有的設(shè)備均由同一個虛線框內(nèi)的 PCL root 連接。
英特爾 Xeon Phi 和 Omni-Path 系統(tǒng)的拓撲結(jié)構(gòu)
MPI_AllReduce 時間是在英特爾 Xeon Phi 7250 處理器上測定的——在英特爾內(nèi)部的帶有 fat-tree 拓撲的 Intel® Omni-Path Architecture (Intel® OPA) series 100 fabric 結(jié)構(gòu)的 Endeavor 集群上,使用了 Intel MPI 5.1.3.181。
3. 結(jié)果
在這部分,我們記錄了一些運算的表現(xiàn)。下面這些結(jié)果是隨機挑選的,它們只是為了演示幾個應(yīng)用的運算表現(xiàn)。下面的結(jié)果僅包括了特定操作和參數(shù)下最快的處理器的時間和浮點運算速度。完整的結(jié)果可以在庫里查看。
這些軟件庫(例如 cuDNN 和 OpenMPI)和一些硬件系統(tǒng)的細節(jié)同樣在 github 的庫里適用。如有問題,請隨時和我們聯(lián)系。
一旦更多硬件平臺的結(jié)果被發(fā)現(xiàn)可以適用,它們都會被加到庫里面來。我們也歡迎所有硬件廠商為此貢獻結(jié)果。
3.1. GEMM Results
3.2. Convolution Results
3.3. Recurrent Ops Results
周期性的操作內(nèi)核僅能在 NVIDIA 的硬件上運行,而周期性的標準檢查程序也將很快可以在 Intel 的硬件上運行。在今年十月份我們將會得到這些結(jié)果。
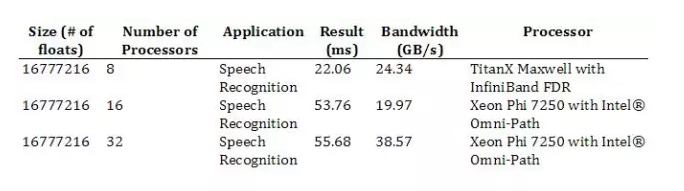
3.4. All-Reduce Results
因為我們僅僅只有一個 Pascal GPU,所有我們不能在 NVIDIA's TitanX Pascal GPU 運行 All-Reduce benchmark。